It seems like every day that goes by, a new AI model comes out. Today (or, yesterday) is certainly no exception, with the release of the new o3 and o4 mini models by ChatGPT. I’ve always been fascinated with new models, and I always try to learn something new every time Twitter explodes over one of these things dropping. So today, I’m going to get right to the chase and dissect my honest first impressions about these two models.
A bit of a disclaimer – these are from a consumer point of view. Despite being a developer myself, I’ve been very underwhelmed by how much these models improve development efficiency, although I surely hope that changes soon. I do like seeing technology from the consumer lens altogether, so that is why the review is on that.
First let’s answer the question – what’s the difference between the two?
o4 mini – The new best model for everyone
Starting off with o4 mini – both of these new models are advertised as “advanced reasoning models” (like we haven’t heard that a million times), and o4 mini is the “miniature” version of the pair. Notably, computations are quick and brief. Reasoning usually never exceeds a couple seconds, with something like the P90 being around a minute.
o3 – The model to push the boundaries
I think I’ve seen around the benchmarks between o3 and o4 mini to be quite comparable in terms of reasoning. That’s because, and I don’t know much technically but, I can assume they use a similar if not identical reasoning model. The difference with o3 I’ve found is that o3 computations are long and concise. I’ve gotten slightly more accurate answers in some use cases just because, it takes substantially longer to analyze things with this. In a lot of cases, you even have the model running for over 10 minutes. Does that mean it’s worth waiting 10 minutes for the answer? Probably not, but it’s fun to see it try.
Capabilities
Going to the capabilities – I like to test a wide variety of different prompts to really push the boundaries of what each new model can do.
With that said, the real strength of these new models is indeed the reasoning. Any task that requires, well, any ounce of thought is going to be better thought out. The logic appears to make more sense than o1/4o, and it seems to extend its resources more.
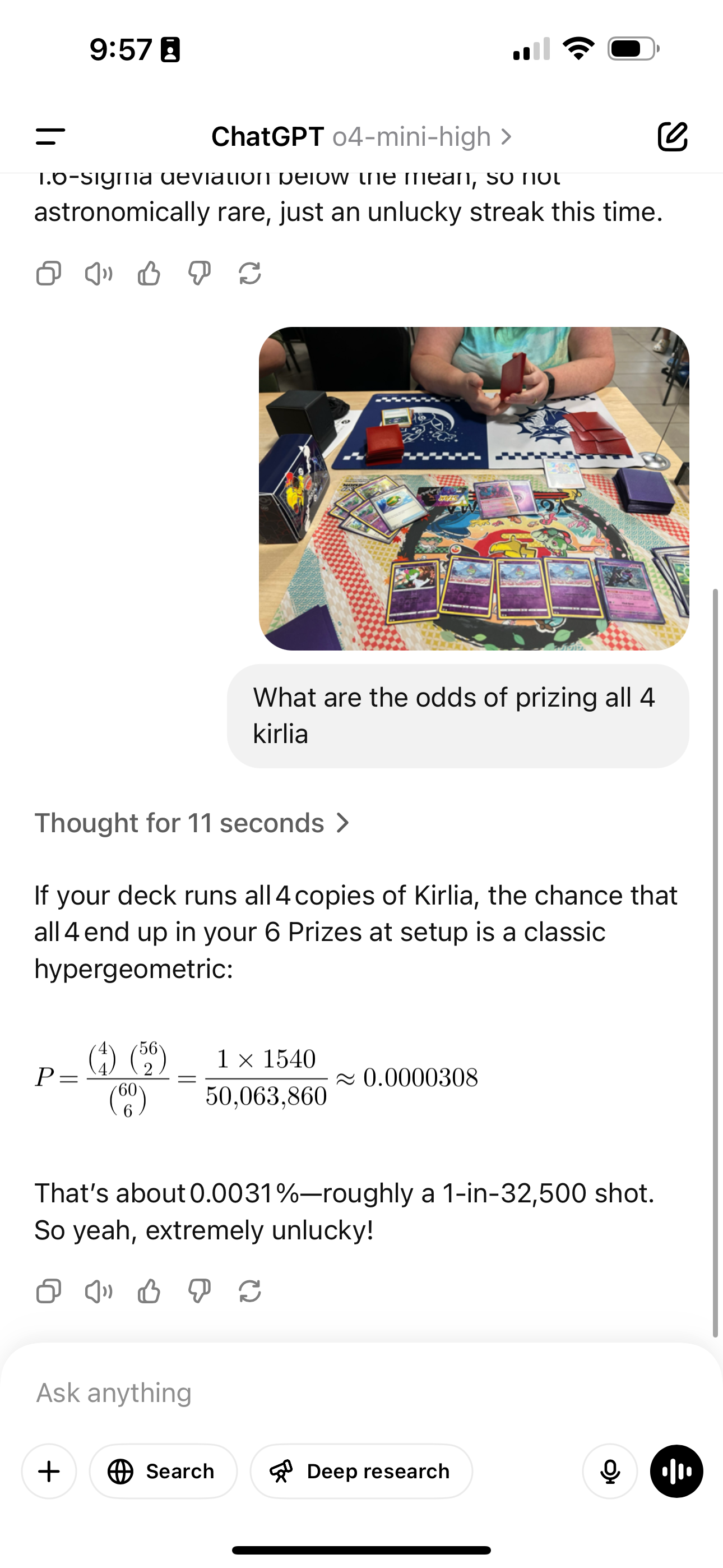
I’m a huge fan of Pokémon cards, so here’s me asking ChatGPT about “prizing” 4 of the same card, Kirlia. In Pokémon, there’s a mechanic where you put 6 cards to the side at the beginning of the match, and take them as you knock out opposing Pokémon. That’s a fact that, I strangely did not have to explain to ChatGPT. It also somehow knew that the standard deck construction was 60 cards, and was to correctly interpret what I intended by my question. All in 11 seconds – not bad.
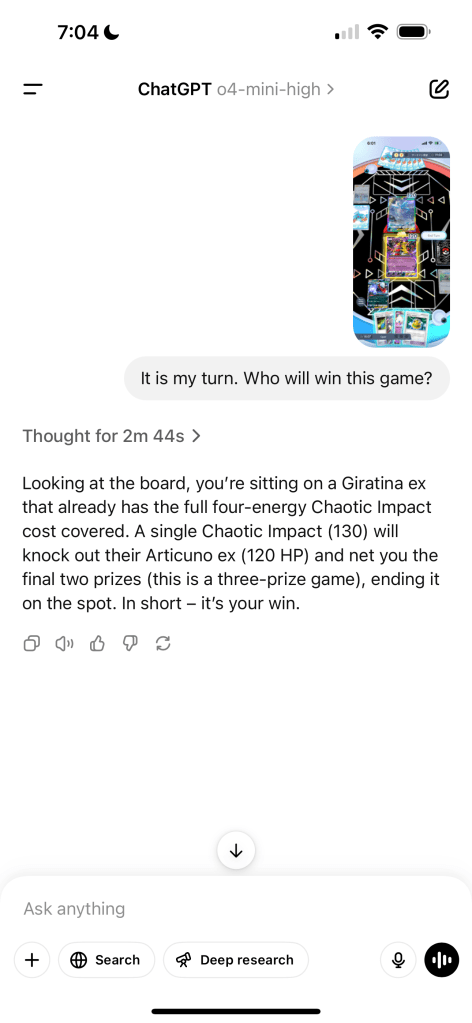
Here’s another question which I asked mini – this time about the mobile game Pokémon Pocket! This game is basically a simplified version of the card game, which, it seems that ChatGPT didn’t know. However, it was still able to correctly analyze that:
- I had enough energies on my Pokémon to attack – each attack has a “requirement” that must be fulfilled in order to declare
- That my attack was enough to knockout the opposing Pokémon, and that it would result in a win
It did take over 2 minutes to figure out, but it’s an insanely impressive testament to exactly how far the AI will go to reason on its own. Despite knowing virtually nothing about the game I was playing, it was able to answer my question with astounding accuracy just by figuring stuff out. The model now seems to use contextual clues much better than previous models. And now with ChatGPT’s ability to access previous knowledge of other conversations, I can see this becoming really useful really quickly the more you use it.
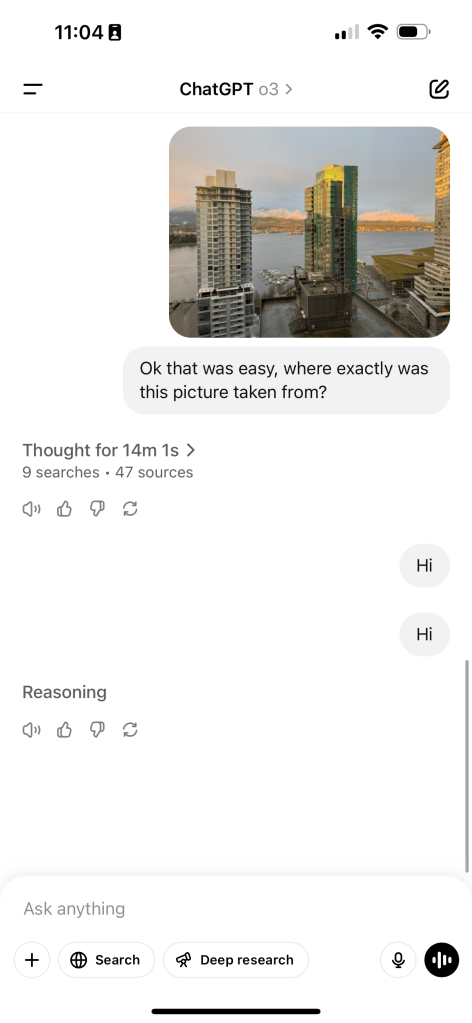
Of course, there are obviously still issues. Here’s a picture I took from a hotel in Vancouver. While it, in the reasoning, actually narrowed it down to two specific hotels, one of them being the correct one, it was unable to wrap it up and deliver an answer. It went on for maybe 5 minutes after correctly solving the problem looping back on itself, and weirdly, it kept zooming in to that little sign in the upper right for like another 5 minutes trying to read it. It did get most of the way there, but was unable to deliver an answer and ultimately ended up becoming unresponsive.
It’s funny, despite how smart LLMs are, we still find them in infinite feedback loops with themselves, just like us humans. I think these models might be slightly better for coding than previous ChatGPT models because of their ability to reason further from context (which coding has quite a lot of), but because they still do spiral out of control, I can’t say this time will be the fix that all of us developers were dreaming of. Sorry, Twitter influencers.
I look forward to seeing what OpenAI and the rest of the bunch build in the upcoming days and weeks, this is truly insane stuff we’re seeing.

Leave a comment